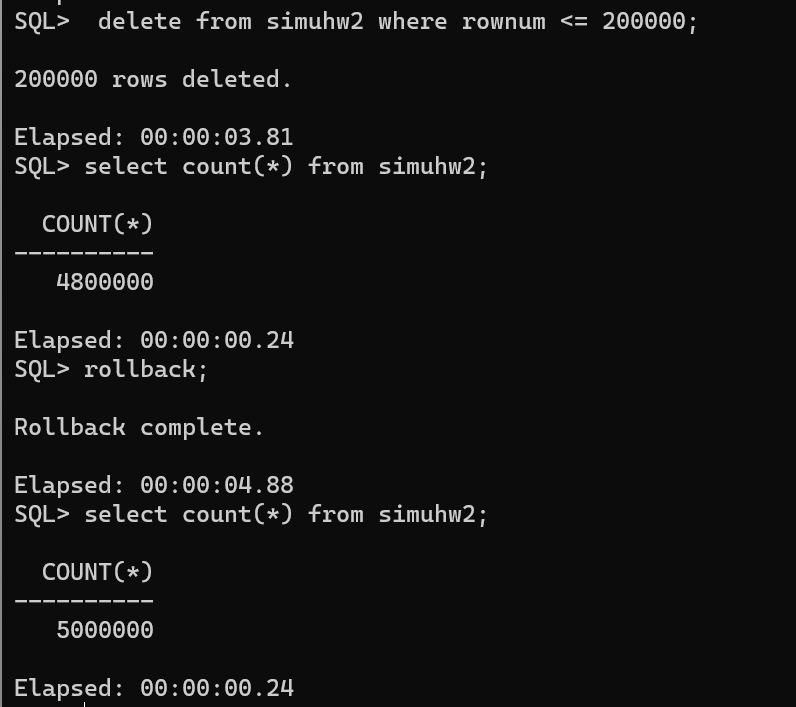
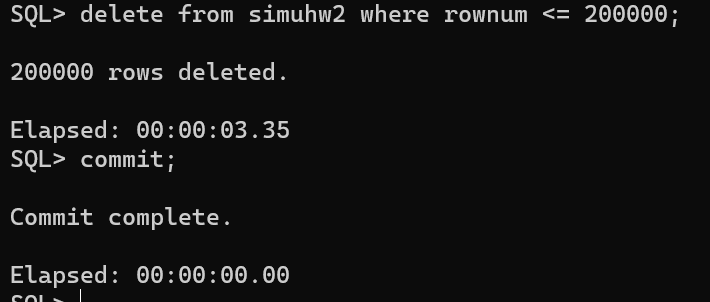
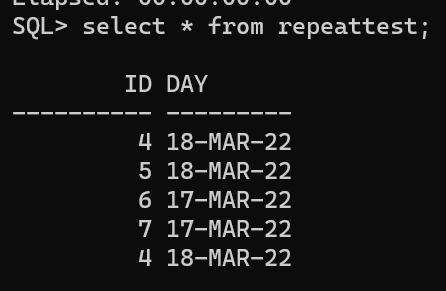
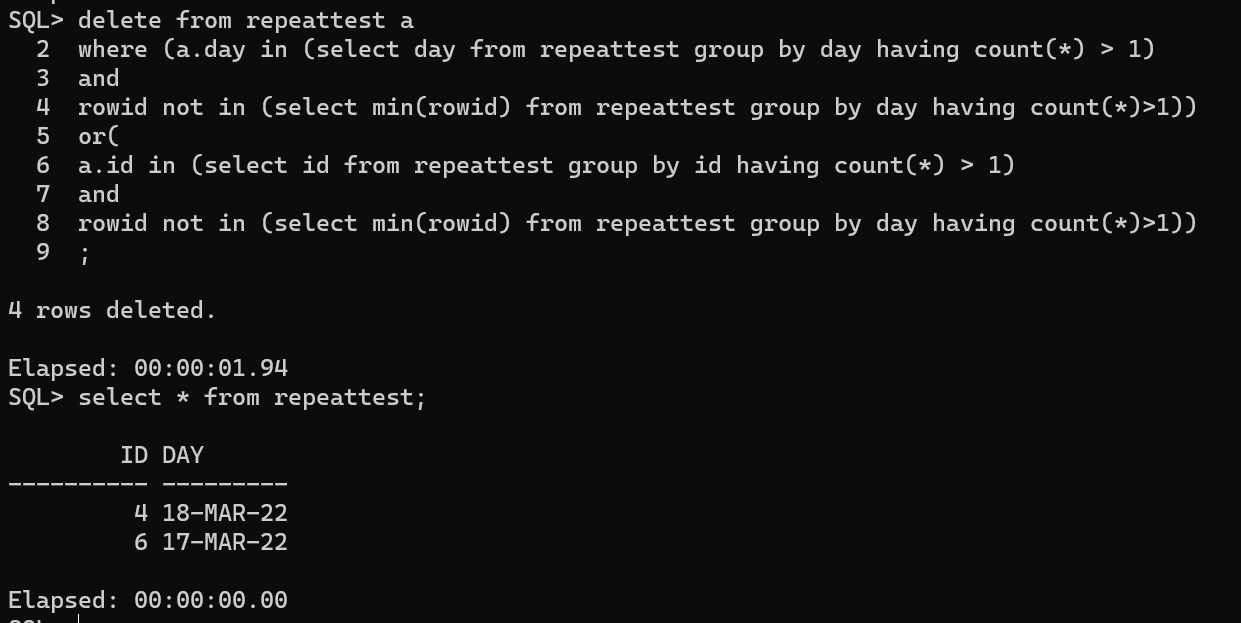
deletefrom repeattest a where (a.day in (selectdayfrom repeattest groupbydayhavingcount(*) >1) and rowid notin (selectmin(rowid) from repeattest groupbydayhavingcount(*)>1)) or( a.id in (select id from repeattest groupby id havingcount(*) >1) and rowid notin (selectmin(rowid) from repeattest groupbydayhavingcount(*)>1)) ;
image-20220318183650192
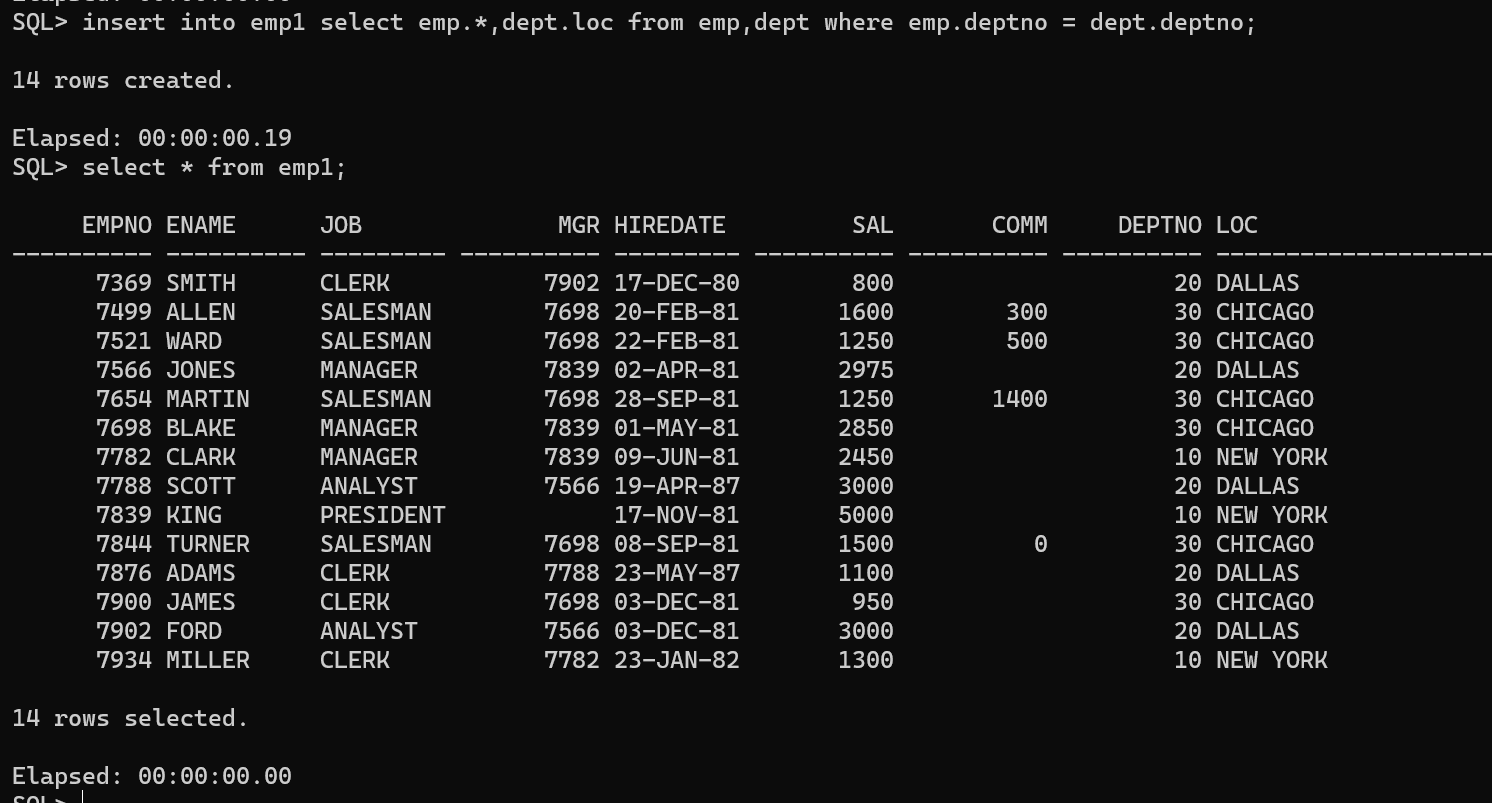
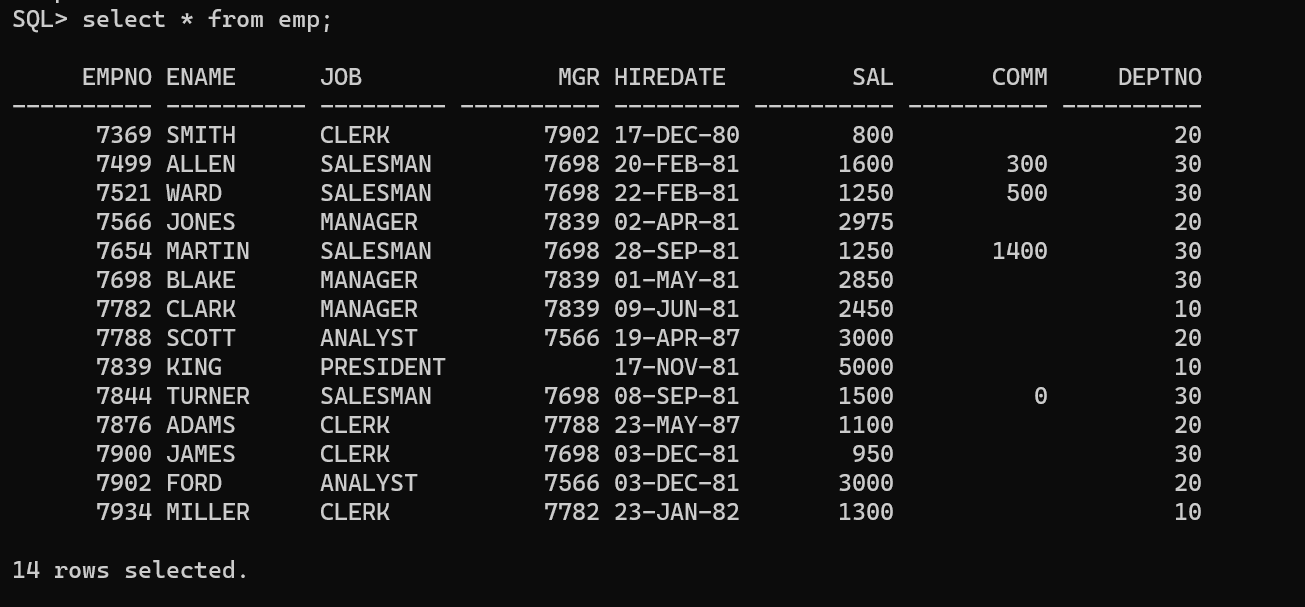
给 EMP 表增加一列 LOC,然后记录每位员工所在城市
先复制表结构
1
createtable emp1 asselect*from emp where1=2;
新建列LOC
1 2
ALTERTABLE emp1 ADD LOC varchar2(20);
1
insertinto emp1 select emp.*,dept.loc from emp,dept where emp.deptno = dept.deptno;
image-20220318200131880
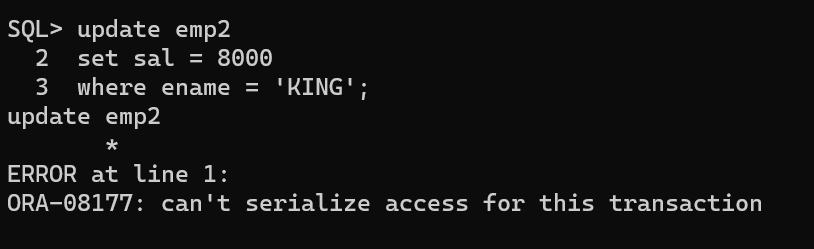
通过 ALTER SESSION SET ISOLATION_LEVEL=SERIALIZABLE;
改变会话的隔离级别,观察事务读写隔离逻辑的影响(缺省的隔离级别是 READ
COMMITTED) 提示:打开 2 个 sqlplus 窗口,都用 scott
登录,在其中一个进行 update 或 commit,在另外
一个窗口观察数据的变化
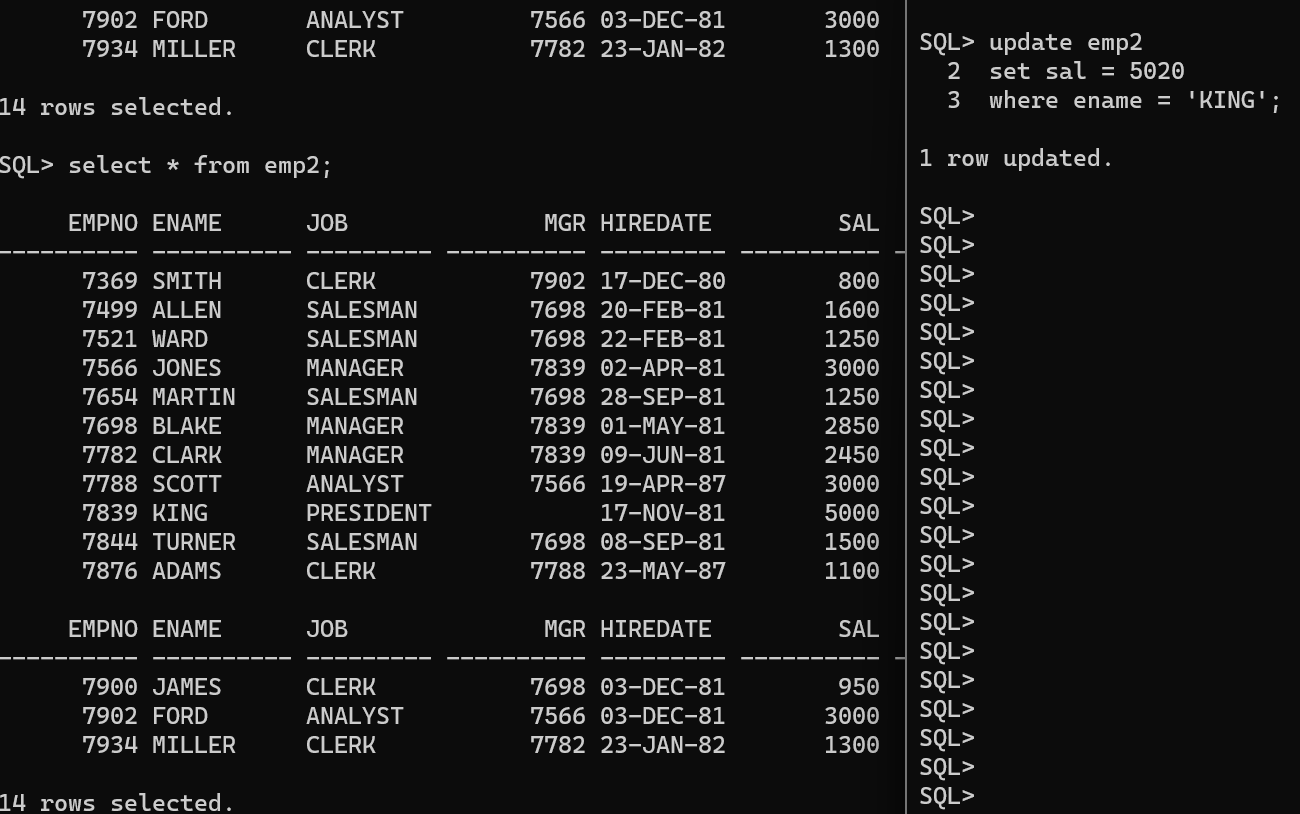
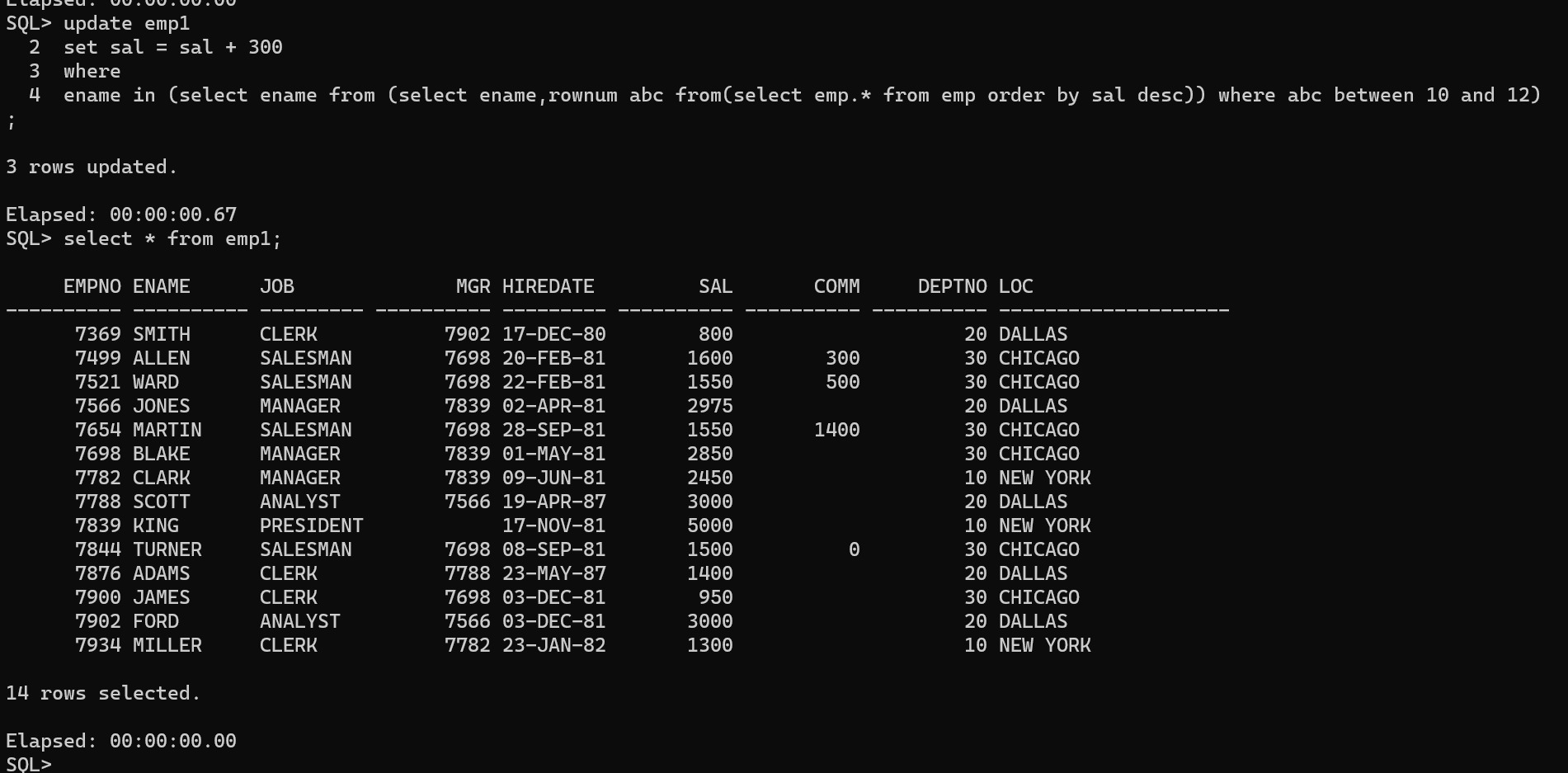
update emp1 set sal = sal +300 where ename in (select ename from (select ename,rownum abc from(select emp.*from emp orderby sal desc)) where abc between10and12);
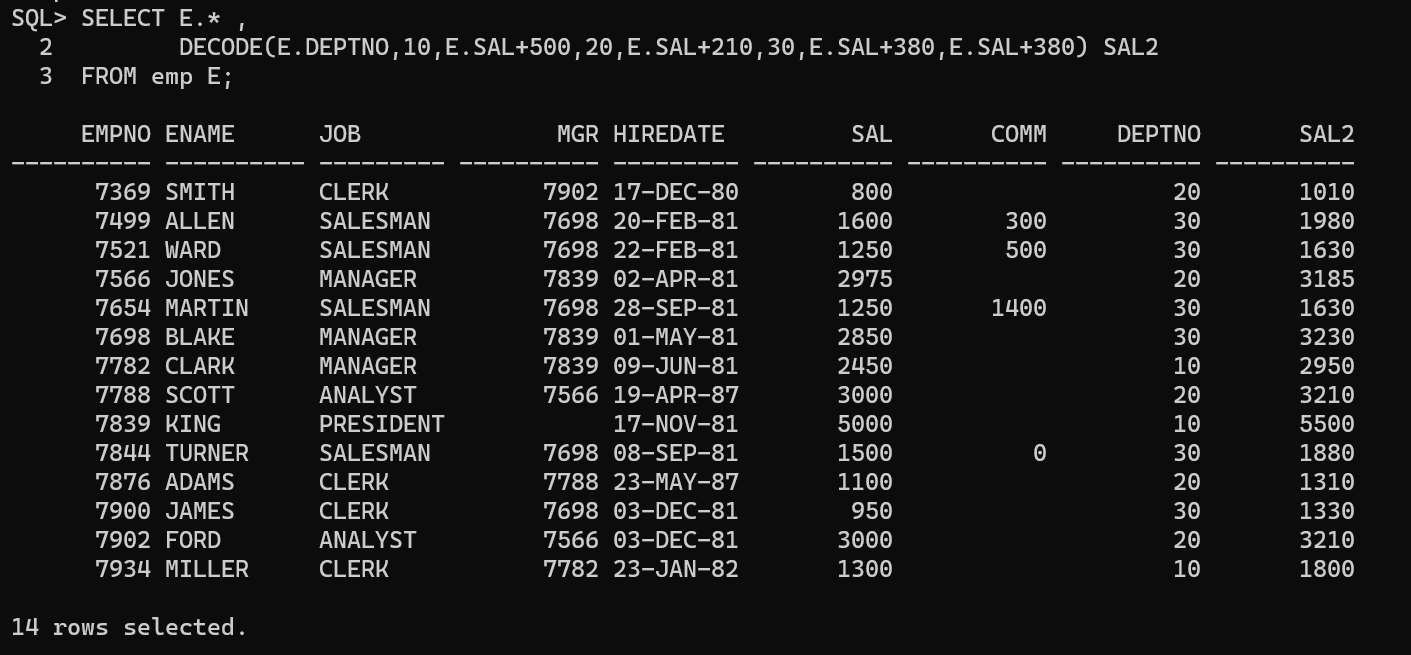
select*from (select a.ename mgrname,b.ename empname,a.sal mgrsal,b.sal empsal from emp a,emp b where a.empno=b.mgr) t where t.empsal>t.mgrsal;
image-20220318210728630
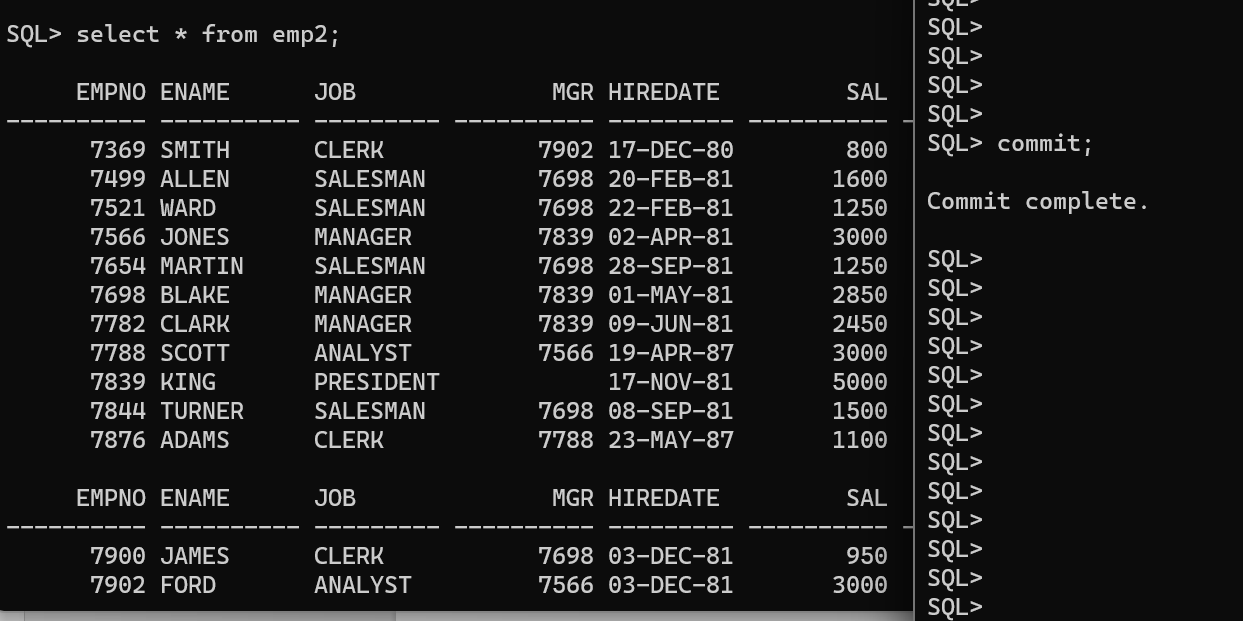
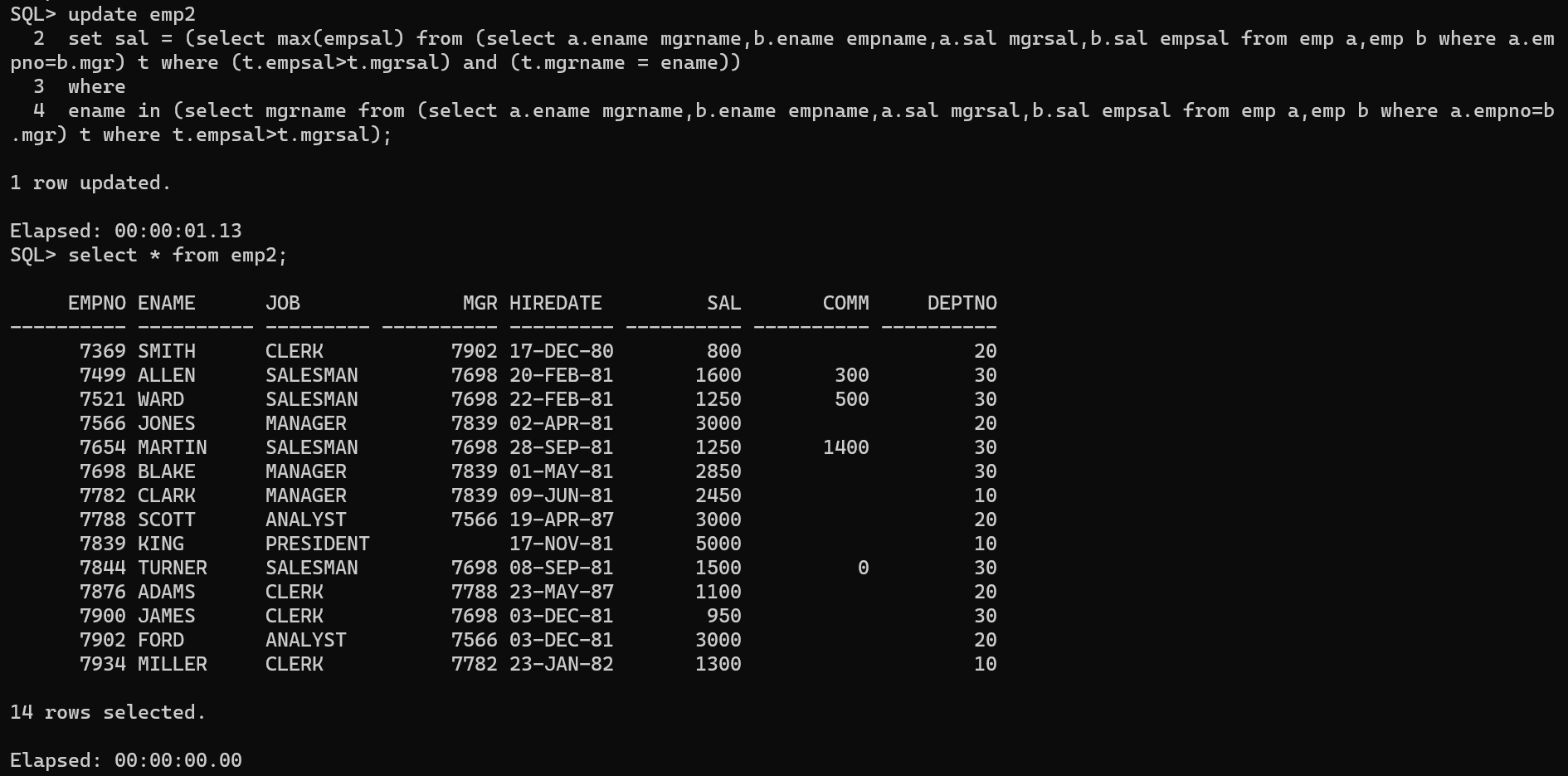
一条语句修改
1 2 3 4
update emp2 set sal = (selectmax(empsal) from (select a.ename mgrname,b.ename empname,a.sal mgrsal,b.sal empsal from emp a,emp b where a.empno=b.mgr) t where (t.empsal>t.mgrsal) and (t.mgrname = ename)) where ename in (select mgrname from (select a.ename mgrname,b.ename empname,a.sal mgrsal,b.sal empsal from emp a,emp b where a.empno=b.mgr) t where t.empsal>t.mgrsal);
image-20220318210928617
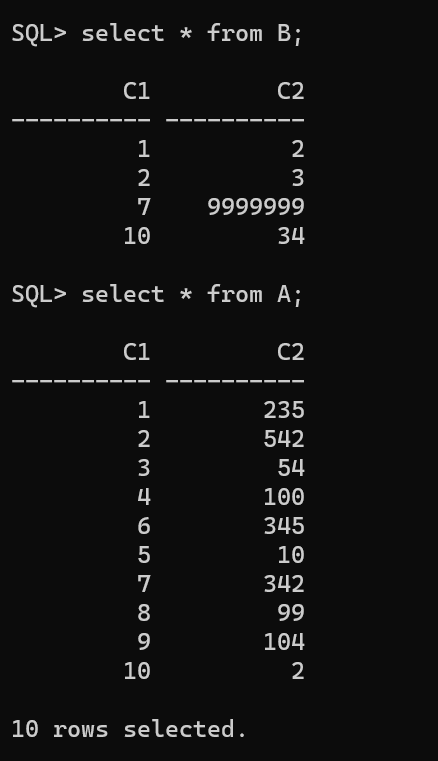
表 A 有 C1,C2 两列,分别记录了所有商品编号(唯一)和商品价格,表 B
也有 C1 和 C2 列,记录了部分商品(非全部)的新价格,请用 B 的数据更新 A
表中的商品价格
1 2 3 4 5 6
createtable A( C1 number notnullprimary key, C2 number notnull); createtable B( C1 number notnullprimary key, C2 number notnull);
采用sqlldr命令导入表格,有:
image-20220318212122583
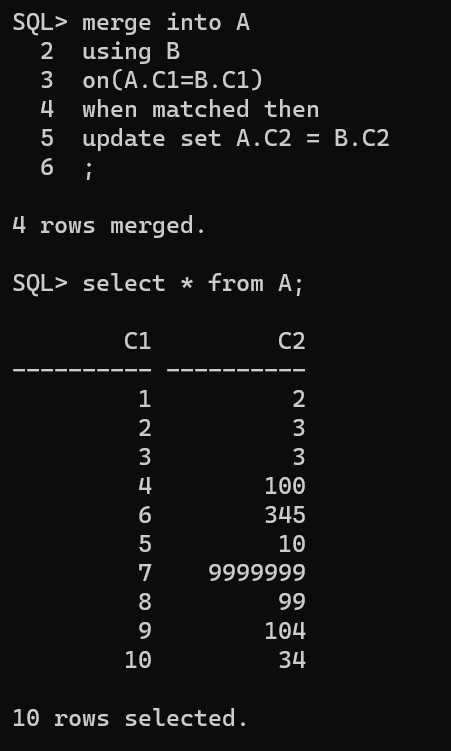
利用 B 的数据更新 A 表中的商品价格
1 2 3 4 5 6
mergeinto A using B on(A.C1=B.C1) when matched then update set A.C2 = B.C2 ;